要明白抽樣的意思是什麼,必先辨別母群
(population) 和樣本 (sample) 兩個概念。母群是探究的全體對像,樣
本則是通過特定抽樣程序所抽查之對象。
|
例子 |
題目 |
母群 |
樣本 |
|
1 |
香港中學生對校規的看法 |
全香港所有中學生 |
來自10間香港中學的100名學生 |
|
2 |
來自國內之新移民所遇到的歧視問題 |
來自國內的所有新移民 |
20個來自國內的新移民 |
|
3 |
香港報章如何報導西藏事件? |
有關西藏事件的所有香港報章報導 |
兩份香港報章於 |
問題是,我們應以什麼準則抽取樣本?
以上表為例,我們如何能確保所抽選的100名中學生能反映全港中學生對校規之看
法?來自不同年級、性別或成績組別的學生會否在這問題上有顯著的差別?來自不同階層和語言區域的新移民的歧視經驗又會否不同?持不同政治傾向的報章又會否
在報導上有系統性的分別?
我們須在探究的最初階段盡量充實我們
對這方面的認識,在抽樣時採用適當的程序,以減低任何削弱代表性的可能。抽樣方法主要分機率 (probabilistic) 和非機率 (non-probabilistic) 兩類,基本概念是要增加隨機性 (randomness),儘量減低個人偏見 (bias) 或盲點導致的偏差。
量性分析採用的主要是機率抽樣。在這
種情況下,母群中每個成員被抽選的機率是可計算評估的。例如,在街頭訪問時,我們很容易邀請面帶笑容的行人接受我們的訪問,但由於性別上的差異,結果我們
可能得到一個女性佔大多數的樣本。要減少這方的問題並不困難。我們可定下一些簡單的規矩,如每隔五個路人訪問一個,讓我們的樣本不致出現「以貌取人」的問題。
又假設我們在校內進行訪問,我們可考
慮每個級別隨機抽選一班,然後每班內再隨機抽選若干受訪同學。這樣有系統地逐層進行抽樣,遠較隨意在操場訪問同學來得有代表性。另外,如同學一早已鎖定某
些重要的變項(如性別),更可把相關的母群一早分開兩個次類別抽樣。這樣便能更準確地測量目標的相關關係,令結論效度更高。在實際探究中,機率抽樣並不一
定可行。在這些情況下,探究員只能進行非機率抽樣,根據便利原則或個人判斷去盡量強化資料的代表性。
以下是有關進行科學抽樣之進階討論,
包括各種抽樣方法的詳細討論和示範,以及量性和質性抽樣之主要分別,內容較為艱深,若有不明白,不妨重溫多遍。
抽樣之進階討論
科學抽樣 (scientific sampling):
- 機率抽樣法 (probabilistic sampling methods)
非機率抽樣法
(non-probabilistic
sampling methods):
- 便利抽樣 (convenience sampling)
- 配額抽樣 (quota sampling)
- 滾雪球抽樣 (snowball sampling)
- 立意抽樣/判斷抽樣 (purposeful
sampling)
科學抽樣 (scientific sampling)
機率抽樣
法
(probabilistic sampling methods)
量性分析
採用的主要是機率抽樣。在這種情況下,母群中每個成員被抽選的機率是一致,並可計算評估。最常見的包括簡易隨機抽樣、系統抽樣、分層抽樣和集體抽樣。
簡易隨機抽樣 (simple random sampling,後稱 SRS)
隨機抽樣
方法其中一個最簡單而又人所共知的例子是博彩攪珠,也就是六合彩。假設每顆彩珠的重量是一致, 而彩珠的
排位不會影響攪動後被抽選的機會,則整個攪動過程便屬隨機,即
每一顆彩珠被抽取的機率皆是均一。
現實上,
無論我們對母群的屬性如何了解,我們始終無法百份百確定母群中有否其他因素左右屬性的分佈。簡易隨機抽樣的原理便是確保母群中每一個單位都有同樣被抽選為
樣本的機會。那麼即使當中有任何我們認知範圍以外的變異分佈,也盡量能在最終樣本中表現出來。
又假設A公司進行
一項家居電話服務調查,並把完整的家居電話資料輸入了電腦,然後進行隨機撥號抽樣。電話成功撥通後,便向第一個接聽電話的住戶進行訪問。這樣的抽樣方法看
似隨機,其實已引進偏差。原因是例子中實有兩輪抽樣程序:
|
|
隨機 |
不隨機 |
|
第一輪抽
樣:電話號碼 |
|
|
|
第二輪抽
樣:住戶代表 |
|
|


為何第二
輪抽樣欠缺隨機性呢?關鍵在於接聽電話的住戶代表是否隨機,意指住戶中所有合資格接受訪問的成員是否都有均一被選的機會。視乎撥電的時段,接聽電話的住戶
成員會有所分別。例
如,上午接電話的多是家
庭主婦或留在家中的長者。他們對家居電話服務的意見可能與在職成員有所不同。由於前者成為樣本的機會比後者為高,抽樣過程並不隨機。要解決這問題,可在接
聽電話以後,先問明適合受訪(如滿18歲)之住
戶成員數目,再以即時隨機抽樣的方法決定誰是受訪對象。
- 坊間多以 街頭抽樣進行訪問,以為這便是隨機抽樣,其實大錯特錯。例如,某團體曾經在銅鑼灣的街頭進行一項有關假日消費意欲的調查。然而,銅鑼灣商場林立,是眾所週 知的購物熱點。相對其他非購物區,在這區流連的行人極可能表現更強的消費意欲。如是者,探究結果告知我們什麼?所謂的結論 -- 如香港人 假日購物意欲高漲-- 是否客 觀?探究設計本身早已自圓其說,抽樣方法已預設結 論。這類探究設 計,須避免之。
|
|
隨機 |
不隨機 |
|
第一輪抽
樣:地區 |
|
|
|
第二輪抽
樣:個人 |
? |
|
簡易隨機
抽樣(SRS)看似簡
單,但執行上並不容易。遇上元素數目龐大的母群,操作時更是相當繁瑣。正因如此,探究員較常採用系統抽樣。做法是系統地選擇抽樣名單的每 x 個元素來
組成樣本。假設1至20之號碼為
母群元素,而抽樣間距 (x)
定為 5,則相關
的樣本便是 1、 6、 11和 16。 例如,我
們可能進行一項有關首映觀後感的探究。與其「隨意」抽取任何
一個步出戲院的觀眾做訪問,我們可做即場的系統抽樣,訪問每五個離開戲院的一位觀眾。這
做法比「隨意」抽樣較為
科學,避免個人偏見可能導致的偏差。例如,我們可能主觀地覺得某些人面目可憎,偏見地以為對方一定會拒絕我們訪問,而只「隨意」挑選一些
看來較友善,或我們主觀認為會接受訪問的人群。這樣做會導致每個元素被選的機會不一致,減低樣本的代表性。
|
母群元素
(綠色格數為所抽選之樣本) |
|||||||||
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
系統抽樣 比簡易隨機抽樣容易操作。然而,我們需留意母群元素排序有否潛藏一種週期性。假設我們需要在K中學四個 年級,每級抽選一班做訪問,而以下是校方提供的母群名單:
|
母群元素 |
|||||||||
|
|
1B |
|
1D |
1E |
|
2B |
|
2D |
2E |
|
|
3B |
|
3D |
3E |
|
4B |
|
4D |
4E |
依照先前
之範例,每五班選一班,我們會選出四個年級的所有A班同學做訪問。這是否一個隨機的選擇呢?關鍵在於分班方法是否隨機,而A至E這排序有
否呈現一定的系統形態。假設K中學是以
成績來分班,則A、B、C、D的排列其
實反映了學生表現之優劣。如是者,我們抽選的樣本便出現週期性誤差 (periodicity bias) ,而實際
受訪的同學將只代表精英班的意見,無法做到隨機抽樣的效果。
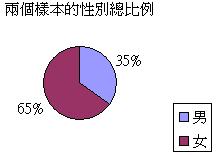
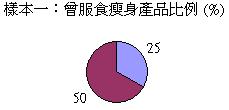
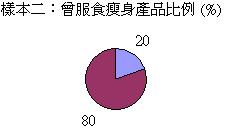
在界定什
麼是分層抽樣之前,讓我們先探討一個例子。假設我們正進行一項有關服食瘦身產品習慣的探究,而以下是來自同一個母群,兩個隨機抽選的樣本:
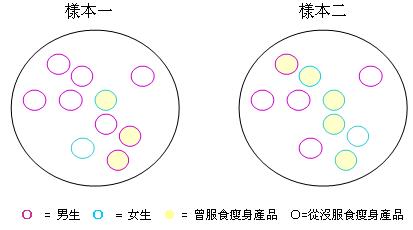
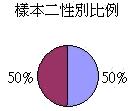
我們會發
現兩個樣本的數據差異頗大,曾服食瘦身產品的比率分別是30%和50%。這差異
反映正常的隨機分佈,抑或抽樣過程
出現的偏差呢?其實兩個樣本
的性別比例相差甚遠,而問題正源自性別和服食瘦身產品的相互關係:
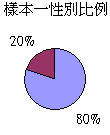 |
 |
 |
 |
 |
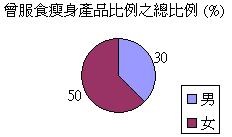 |
根據上述
資料,女性服食瘦身產品的比率較高。如是者,我們須確保抽樣程序顧及這變項因素。例如,我們可
先把母群分開兩個組別,即男生與女生,然後才在這兩個組別進行抽樣。
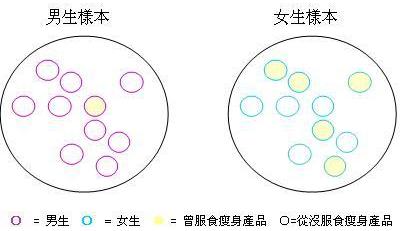
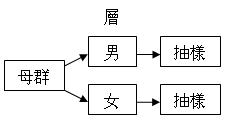
以上方法 便是分層抽樣。分層抽樣並不是以上兩種方法 的代替品,而是一種修正的抽樣程序。層 (stratum) 是根據母 群中的個體屬性類分之互斥組別,如性別、種族、收入等。分層的概念是先將母群分為相關的層,才在每層中隨機抽取樣本。分層的好處是增加次母群之共通性,亦 幫助我們更有系統地探究不同變項之間的相互關係。
|
以性別為
層的例子: |
|
|
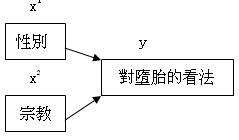
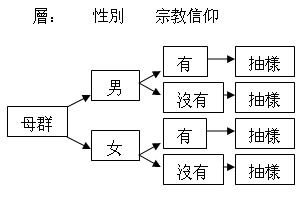
同一個母
群可通過多重的分層處理。假設我們要解釋不同人對墮胎的看法 (下稱 y), 而可能相
關的變項包括性別和宗教信仰。我們一方面希望能系統地探究三者的關係,固必須在探究時蒐集完整的相關資料。例如,我們可能選擇以問卷形式進行探究。如是
者,則問題中必須包
括對方性別、宗教信仰以及對墮胎之取態的問題。與此同時,我們須確保數據的結果是有效地反映兩個 x 的影響,
而不是源自其他探究步驟 -- 如抽樣 -- 出現的偏
差。在這種情況下,我們可先作分層處理,確保沒有一個次母群出現過份代表 (over-represented)的情況:
|
|
|
在理想的情況下,探究員須先備有一份完整的母群表列名單,才能進行先前提及的抽樣方法。假設我們的母群是春田省所有中學生,而春田省共有A、B、C、D、E五個區
域,而每個區域皆有兩所中學,則此母群之完整表列名單如下:
|
例子:春
田省中學生調查 |
|
|

要拿得母
群完整的表列名單並不是容易的事。這帶來操作上的困難,亦令過程變得繁複。類聚抽樣是一個常用但較易操作的機率抽樣方法。做法是先把母群分為若干集體部
落,或所謂的類聚 (cluster),如國
家、地區、大廈、居住樓層、學校、學班,然後先從這些類聚中隨機抽樣。當類聚抽樣完成後,才搜集相關之表列名單,進行最終之樣本 抽樣。
|
例子:春
田省中學生調查 |
|
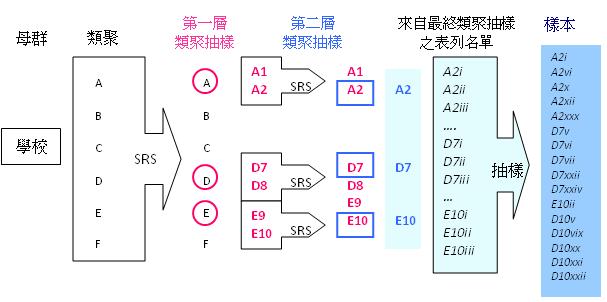 |
多重類聚抽樣 (multi-stage cluster sampling)
視乎需
要,探究可進行一輪或多於一輪的類聚抽樣。以上例子便進行了兩輪的類聚抽樣:
|
|
第一輪 |
第二輪 |
|
類聚 |
區域 (A、B、C、D、E) |
學校 (A1、A2、D7、D8、E9、E10) |
類聚抽樣
雖然帶來相當的利便,但卻有可能因為類聚之間的分別而出現一個欠缺代表性的樣本。一般而言,類聚的數項越多,而每個類聚以內的表列清單越短,則會出現系統
偏差的機會會較低。
在實際探
究中,學生可同時採用不同的抽樣方法。假設同學要在校內進行有關校規看法的探究,以下是各項可行的抽樣方法:
|
探究題
目:香港中學生對校規的看法 |
||||
|
抽樣方法 |
母群 |
所需資料 |
程序 |
|
|
單一抽樣
方法 |
SRS
或系統抽樣 |
校內所有
同學 |
校內所有
同學之完整表列名單 |
從名單中
進行SRS或系統抽
樣 |
|
雙重抽樣 |
分層抽樣 |
1.
把母群表列名單分層 |
||
|
類聚抽樣 |
母群的類
聚名單(如班別),以及被抽選之類聚(如抽選的5B班) 的完整表
列名單 |
1.
把母群分為類聚,然後進行類聚隨機抽樣 |
||
非機率抽
樣法
(non-probabilistic sampling methods)
在實際探
究中,機率抽樣並不一定可行。在這些情況下,探究員只能進行非機率抽樣。常用的方法包括便利抽樣法、配額抽樣、滾雪球抽樣和立意抽樣,簡述如下:
- 便利抽樣 (convenience sampling)
- 配額抽樣 (quota sampling)
配額抽樣
和分層抽樣有點相似。探究員會根據她對母群屬性的認識定下一些類分指標(如性別),然後按這些變值定下樣本配額(如須訪問多少男生和女生)。不同的是,分
層抽樣屬機率抽樣的一種,本質上採用隨機原則;配額抽樣則依靠探究員有限的認知和主觀的判斷去確立配額,屬非機率的抽樣方法。
- 滾雪球抽
樣
(snowball sampling)
當母群中
的表列名單層並不明確的時候,我們須首先接觸具有相關屬性的人,然後通過他們的網絡,滾雪球般一個介紹一個的接觸更多樣本,直至認為資料已足夠為止。例
如,我們無法確認那些年青人曾經服食精神科藥物。然而,我們可先接觸少數有此經驗的年青人,然後通過她們介紹網絡中的其他個案,幫助我們滾雪球般慢慢累積
所需的樣本。
- 立意抽樣/判斷抽樣 (purposeful sampling)
立意抽樣
的意思是根據探究員對母群的認識和判斷去抽選他認為最具代表性的樣本。
量性統計
分析必須建基於機率抽樣之上。質性分析並不倚重量化數據,強調的是理論上的概括性而不是從樣本概括至母群的代表性,固所用之抽樣方法亦不局限於機率形式,
較常採用非機率抽樣。
|
|
如所得之
數據將用諸更大的母群,則無論採用的是量性或質性方法,抽樣方法都必須具備機率上的代表性。另一方面,如探究的目的純為了解和深化某些概念上的認知,而不
是量化地概括至更大母群,則採用非機率抽樣亦是可行。
|
|||||||||||||
|
|||||||||||||

